Like Regular LINQ, but Faster and Without Allocations: Is It Possible?
Hello, my fellow ducks!

Don’t most of us like LINQ? That amazing part of Base Class Library that .NET is shipped with today, which allows to work with sequences declaratively. However, what if we make a “better” version of it?
For the impatient: github.
In short about how Linq works
In nutshell, LINQ is just a set of extension methods over IEnumerable<T> interface. Every method creates another “layer” over the previous sequence, adding new conditions or transformations of elements of that sequence. For example, Select creates SelectEnumerableIterator and returns it (unless other optimization tricks did their job).
Whenever you foreach over a sequence created with those methods, you create a enumerator, and step with it. Here’s how foreach is lowered:

It is not the precise expansion of foreach, visit sharplab if you want to know what exactly happens there.
Now… that and other iterators are all classes, meaning that every time you call Select/Where or other LINQ’s methods, a new instance of reference type gets created on managed heap, adding GC pressure. GC works blazingly fast in .NET, but sometimes these allocations are undesired. Also, when those iterators are ran (when you do an active action, e. g. Count(), Sum(), or go over it with foreach), a level of indirection is created due to a virtual call (call to the interface).
Let’s make our Linq
The idea here is that instead of having that one single common interface that every new instance is upcasted into, we would have a far more complicated type, which would accumulate all iterators, all queries.
All we want to do is to store the previous iterator instead of the current one. The way to do it — is generics. Oh yeah, I love generics, as you could’ve guessed by my previous article. This time we are going to make the type of the previous iterator a type parameter. Here’s how:

Now TEnumerator is the previous enumerator itself given that it’s a struct. Now, how do we make Select then? Let’s make SelectEnumerator first:

As you see, it holds the previous enumerator and a delegate, which maps from T to U (e. g. from int to string). This enumerator iteraters over the previous enumerator and sets Current to the new value (the value from previous enumerator mapped through the delegate). TDelegate is a type argument for delegates, so that one could pass a value delegate in there if wants to avoid a call.
Now, the Select method itself just creates the enumerator. You know, LINQ works lazily, so does our RefLinq. We just create an enumerator and return it — it will be ran on demand.
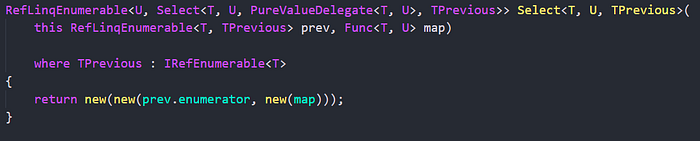
Same way we create Where and other enumerators. Now, like I said, the enumerator holds the previous one in it. Let’s look at the actual type we get:
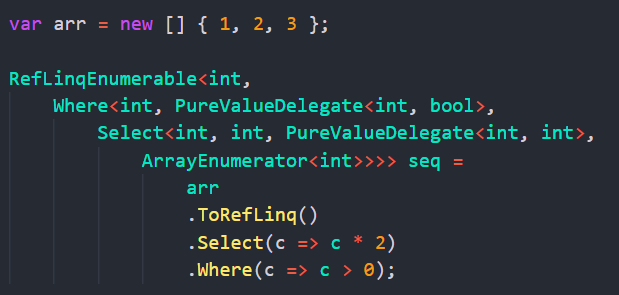
As you see, the innermost one is ArrayEnumerator, it’s embedded into a Select one, and the outer one is Where. Select has a pure value delegate from int to int, Where likewise has delegate from int to bool (predicate).
So instead of having a common interface into which we upcast all our iterators, like it works with classic LINQ, we create a new type on every operation, so no heap allocations, absolutely no, happens!
Moreover, as there is no virtual calls and all methods are determined at compilation time, many of them get inlined and boost performance. That is why such an implementation would also be faster!
Why LINQ is not implemented like this?
Because LINQ is implemented far more universal. Let me go over all problems that we have with our implementation.
Problem 1. Copying is expensive
That means, that we cannot ever box our structs into interfaces/objects. Which, in turn, means, that passing our sequence into a method or returning from it would impose a huge performance hit. To pass this struct by copy one would need to copy the whole struct over to the called method:
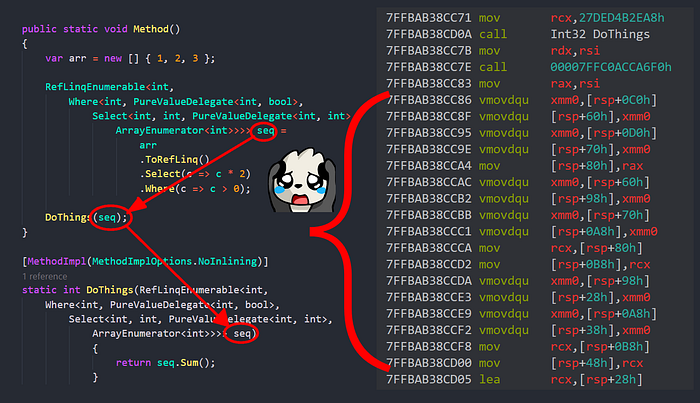
As you can see, this passing introduces a whole bunch of instructions to move copy memory to pass it to DoThings!
Problem 2. No common type — limited abilities
In regular Linq we could easily add a new “layer” to our sequence conditionally or overwrite it, like this:

Classic Linq has common reference type IEnumerable<T>, and thanks to virtual calls the actual underlying type can be any!
But not in our case:
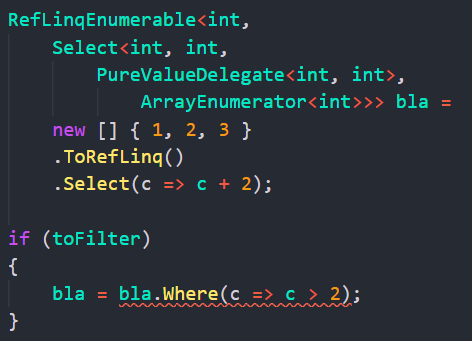
Since it’s all value types and no abstracting interface, we cannot box this new sequence into the old one.
Problem 3. Not all Linq methods can be made stack only
For example, SkipLast would need to store a buffer of elements to ensure that we don’t visit an undesired element, and at the same time, visit other elements no more than once.
I didn’t find any neat way to do it safely. The only way to allocate stack memory dynamically is stackalloc, but it has to be done on the user’s side, and at the same time, the user has to pass the size of the buffer manually to it. It kills the purpose of linq then.
Problem 4. Hungry for stack memory
Most of the time people would care only about heap memory, which is absolutely fair. But in this rare case I also paid attention to the amount of memory allocated on stack — since it’s a huge struct, remember? It would eat a lot of stack.
Using my own alpha-versioned CodegenAnalysis tool I inspect the amount of stack allocated memory:
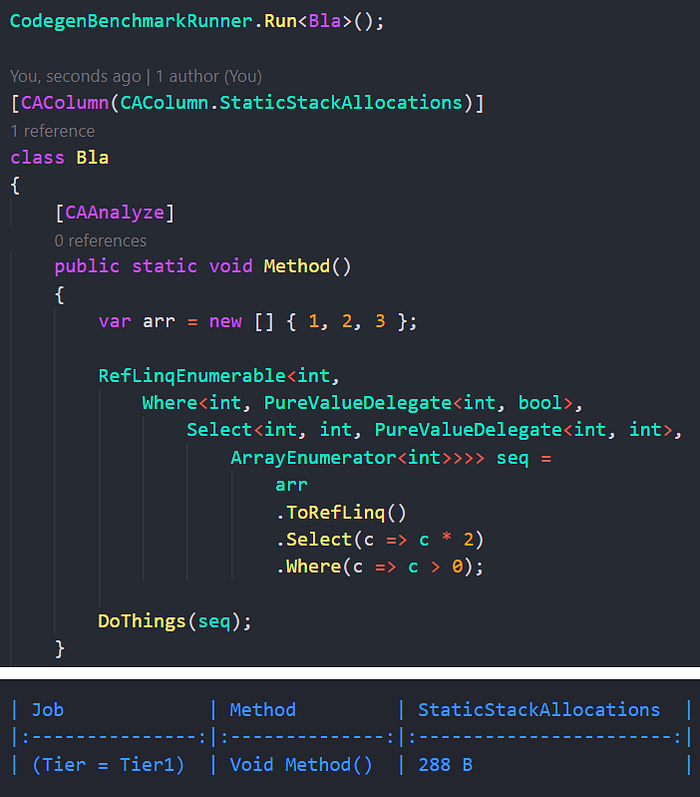
288 bytes allocated on stack. And it’s just Select and Where! With long and complex queries it can be kilobytes. (note that this size does not depend on the size of the input, since it’s all enumerators)
Does anybody need it?
Yes, but not many. It may be needed by game developers, system programmers, or those whose scenarios exactly fit the use case of the lib (that is, without returning/passing those enumerators, using some methods which would need buffer, etc.).
In fact, what I made is absolutely not new as an idea, I just described how it works, how useful it is or not. There are plenty of other libs for the same purpose: NoAlloq, LinqFaster, Hyperlinq, ValueLinq, LinqAF, StructLinq. They all differ from each other a little bit, but follow more or less the same idea.
Conclusion
I implemented all but only methods which can be made stack only. To compare perf characteristics to other libs, refer to the Benchmarks section of the repo.
So, in the end, this implementation would have a much lower or even zero overhead compared to manually implemented state machines (for loops would be still faster). There’s no virtual calls, and there’s no heap allocations.
But it has many negative implications: no common type to upcast to, some methods cannot be implemented, copying is expensive, etc.
So I declare classic Linq the winner here. However I still think that the article is useful — in a sense, that yes, there’s no better linq than built-in linq, but there’s a way to make it better for some niche scenarios.
Thanks for your attention! My github, twitter.
(I analyze the performance with BenchmarkDotNet, and JIT’s asm codegen with CodegenAnalysis. Screenshots are made in VS Code in Andromeda color theme)

